Chapter 9. Getting Control—Regular Expression Metacharacters

9.1. Regular Expression Metacharacters
Regular expression metacharacters are characters that do not represent themselves. They are endowed with special powers to allow you to control the search pattern in some way (e.g., find the pattern only at the beginning of line or at the end of the line or only if it starts with an upper- or lowercase letter). Metacharacters lose their special meaning if preceded with a backslash (\). For example, the dot metacharacter represents any single character but when preceded with a backslash is just a dot or period.
If you see a backslash preceding a metacharacter, the backslash turns off the meaning of the metacharacter, but if you see a backslash preceding an alphanumeric character in a regular expression, then the backslash means something else. Perl provides a simpler form of some of the metachacters, called metasymbols, to represent characters. For example, [0–9] represents numbers in the range between 0 and 9, and \d represents the same thing. [0–9] uses the bracket metacharacter; \d is a metasymbol.
Example 9.1.
/^a...c/
This regular expression contains metacharacters. (See Table 9.1.) The first one is a caret (^). The caret metacharacter matches for a string only if it is at the beginning of the line. The period (.) is used to match for any single character, including whitespace. This expression contains three periods, representing any three characters. To find a literal period or any other character that does not represent itself, the character must be preceded by a backslash to prevent interpretation.9.39Examples 9.38
Table 9.1. Metacharacters| Metacharacter | What It Matches |
|---|
| Character Class: Single Characters and Digits | | . | Matches any character except a newline | | [a–z0–9] | Matches any single character in set | | [^a–z0–9] | Matches any single character not in set | | \d | Matches one digit | | \D | Matches a nondigit, same as [^0–9] | | \w | Matches an alphanumeric (word) character | | \W | Matches a nonalphanumeric (nonword) character | | Character Class: Whitespace Characters | | \s | Matches a whitespace character, such as spaces, tabs, and newlines | | \S | Matches nonwhitespace character | | \n | Matches a newline | | \r | Matches a return | | \t | Matches a tab | | \f | Matches a form feed | | \b | Matches a backspace | | \0 | Matches a null character | | Character Class: Anchored Characters | | \b | Matches a word boundary (when not inside [ ]) | | \B | Matches a nonword boundary | | ^ | Matches to beginning of line | | $ | Matches to end of line | | \A | Matches the beginning of the string only | | \Z | Matches the end of the string or line | | \z | Matches the end of string only | | \G | Matches where previous m//g left off | | Character Class: Repeated Characters | | x? | Matches 0 or 1 x | | x* | Matches 0 or more occurrences of x | | x+ | Matches 1 or more occurrences of x | | (xyz)+ | Matches 1 or more patterns of xyz | | x{m,n} | Matches at least m occurrences of x and no more than n occurrences of x | | Character Class: Alternative Characters | | was|were|will | Matches one of was, were, or will | | Character Class: Remembered Characters | | (string) | Used for backreferencing (see Examples 9.38 and 9.39) | | \1 or $1 | Matches first set of parentheses | | \2 or $2 | Matches second set of parentheses | | \3 or $3 | Matches third set of parentheses | | Character Class: Miscellaneous Characters | | \12 | Matches that octal value, up to \377 | | \x811 | Matches that hex value | | \cX | Matches that control character; e.g., \cC is <Ctrl>-C and \cV is <Ctrl>-V | | \e | Matches the ASCII ESC character, not backslash | | \E | Marks the end of changing case with \U, \L, or \Q | | \l | Lowercase the next character only | | \L | Lowercase characters until the end of the string or until \E | | \N | Matches that named character; e.g., \N{greek:Beta} | | \p{PROPERTY} | Matches any character with the named property; e.g., \p{IsAlpha}/ | | \P{PROPERTY} | Matches any character without the named property | | \Q | Quote metacharacters until \E | | \u | Titlecase next character only | | \U | Uppercase until \E | | \x{NUMBER} | Matches Unicode NUMBER given in hexadecimal | | \X | Matches Unicode "combining character sequence" string | | \[ | Matches that metacharacter | | \\ | Matches a backslash |
In Example 9.1, the regular expression reads: Search at the beginning of the line for an a, followed by any three single characters, followed by a c. It will match, for example: abbbc, a123c, a c, or aAx3c only if those patterns were found at the beginning of the line.
|
9.1.1. Metacharacters for Single Characters
If you are searching for a particular character within a regular expression, you can use the dot metacharacter to represent a single character or a character class that matches one character from a set of characters. In addition to the dot and character class, Perl has added some backslashed symbols (called metasymbols) to represent single characters. (See Table 9.2.)
Table 9.2. Metacharacters for Single Characters
| Metacharacter | What It Matches |
|---|
| . | Matches any character except a newline |
| [a–z0–9_] | Matches any single character in set |
| [^a–z0–9_] | Matches any single character not in set |
| \d | Matches a single digit |
| \D | Matches a single nondigit; same as [^0–9] |
| \w | Matches a single alphanumeric (word) character; same as [a–z0–9_] |
| \W | Matches a single nonalphanumeric (nonword) character; same as [^a–z0–9_] |
The Dot Metacharacter
The dot (.) metacharacter matches any single character with the exception of the newline character. For example, the regular expression /a.b/ is matched if the string contains an a, followed by any one single character (except the \n), followed by b, whereas the expression /.../ matches any string containing at least three characters.
Example 9.2.
(The Script)
# The dot metacharacter
1 while(<DATA>){
2 print "Found Norma!\n" if /N..ma/;
}
_ _DATA_ _
Steve Blenheim 101
Betty Boop 201
Igor Chevsky 301
Norma Cord 401
Jonathan DeLoach 501
Karen Evich 601
(Output)
Found Norma!
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line following the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line below _ _DATA_ _ is assigned to $_ until all the lines have been processed. The string Found Norma!\n is printed only if the pattern found in $_ contains an uppercase N, followed by any two single characters, followed by an m and an a. It would find Norma, No man, Normandy, etc.
|
The s Modifier—The Dot Metacharacter and the Newline
Normally, the dot metacharacter does not match the newline character, \n, because it matches only the characters within a string up until the newline is reached. The s modifier treats the line with embedded newlines as a single line, rather than a group of multiple lines, and allows the dot metacharacter to treat the newline character the same as any other character it might match. The s modifier can be used with both the m (match) and the s (substitution) operators.
Example 9.3.
(The Script)
# The s modifier and the newline
1 $_="Sing a song of sixpence\nA pocket full of rye.\n";
2 print $& if /pence./s;
3 print $& if /rye\../s;
4 print if s/sixpence.A/twopence, a/s;
(Output)
2 pence
3 rye.
4 Sing a song of twopence, a pocket full of rye.
The $_ scalar is assigned; it contains two newlines. The regular expression, /pence./, contains a dot metacharacter. The dot metacharacter does not match a newline character unless the s modifier is used. The $& special scalar holds the value the pattern found in the last successful search; i.e., pence\n. The regular expression /rye\../ contains a literal period (the backslash makes the period literal), followed by the dot metacharacter that will match on the newline, thanks to the s modifier. The $& special scalar holds the value the pattern found in the last successful search; i.e., rye.\n. The s modifier allows the dot to match on the newline character, \n, found in the search string. The newline will be replaced with a space.
|
The Character Class
A character class represents one character from a set of characters. For example, [abc] matches an a, b, or c, and [a–z] matches one character from a set of characters in the range from a to z, and [0–9] matches one character in the range of digits between 0 and 9. If the character class contains a leading caret (^), then the class represents any one character not in the set; for example, [^a–zA–Z] matches a single character not in the range from a to z or A to Z, and [^0–9] matches a single character not in the range between 0 and 9. To represent a number between 10 and 13, use 1[0–3], not [10–13].
Perl provides additional symbols, metasymbols, to represent a character class. The symbols \d and \D represent a single digit and a single non-digit, respectively; they are the same as [0–9] and [^0–9]. Similarly, \w and \W represent a single word character and a single nonword character, respectively; they are the same as [A–Za–z_0–9] and [^A–Za–z_0–9].
Example 9.4.
(From a Script)
1 while(<DATA>){
2 print if /[A-Z][a-z]eve/;
}
_ _DATA_ _
Steve Blenheim 101
Betty Boop 201
Igor Chevsky 301
Norma Cord 401
Jonathan DeLoach 501
Karen Evich 601
(Output)
Steve Blenheim 101
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line following the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line after _ _DATA_ _ is assigned to $_ until all the lines have been processed. The line $_ is printed only if $_contains a pattern matching one uppercase letter [A–Z], followed by one lowercase letter [a–z], and followed by eve.
|
Example 9.5.
(The Script)
# The bracketed character class
1 while(<DATA>){
2 print if /[A-Za-z0-9_]/;
}
_ _DATA_ _
Steve Blenheim 101
Betty Boop 201
Igor Chevsky 301
Norma Cord 401
Jonathan DeLoach 501
Karen Evich 601
(Output)
Steve Blenheim 101
Betty Boop 201
Igor Chevsky 301
Norma Cord 401
Jonathan DeLoach 501
Karen Evich 601
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line from _ _DATA_ _ is assigned to $_ until all the lines have been processed. The line $_ is printed only if it contains a pattern matching one alphanumeric word character, represented by the character class, [A–Za–z0–9_]. All lines are printed.
|
Example 9.6.
(The Script)
# The bracket metacharacters and negation
1 while(<DATA>){
2 print if / [^123]0/
}
_ _DATA_ _
Steve Blenheim 101
Betty Boop 201
Igor Chevsky 301
Norma Cord 401
Jonathan DeLoach 501
Karen Evich 601
(Output)
Norma Cord 401
Jonathan DeLoach 501
Karen Evich 601
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line from _ _DATA_ _ is assigned to $_ until all the lines have been processed. The line $_ is printed only if $_ contains a pattern matching one space, followed by one number not in the range between 1 and 3 (not 1, 2, or 3), followed by 0.
|
Example 9.7.
(The Script)
# The metasymbol, \d
1 while(<DATA>){
2 print if /6\d\d/
}
_ _DATA_ _
Steve Blenheim 101
Betty Boop 201
Igor Chevsky 301
Norma Cord 401
Jonathan DeLoach 501
Karen Evich 601
(Output)
Karen Evich 601
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line from _ _DATA_ _ is assigned to $_ until all the lines have been processed. The line $_ is printed only if it contains a pattern matching the number 6, followed by two single digits. The metasymbol \d represents the character class [0–9].
|
Example 9.8.
(The Script)
# Metacharacters and metasymbols
1 while(<DATA>){
2 print if /[ABC]\D/
}
_ _DATA_ _
Steve Blenheim 101
Betty Boop 201
Igor Chevsky 301
Norma Cord 401
Jonathan DeLoach 501
Karen Evich 601
(Output)
Steve Blenheim 101
Betty Boop 201
Igor Chevsky 301
Norma Cord 401
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line from _ _DATA_ _ is assigned to $_ until all the lines have been processed. The line $_ is printed only if $_ contains a pattern matching an uppercase A, B, or C [ABC], followed by one single nondigit, \D. The metasymbol \D represents the character class [^0–9]; that is, a number not in the range between 0 and 9.
|
Example 9.9.
(The Script)
# The word metasymbols
1 while(<DATA>){
2 print if / \w\w\w\w \d/
}
_ _DATA_ _
Steve Blenheim 101
Betty Boop 201
Igor Chevsky 301
Norma Cord 401
Jonathan DeLoach 501
Karen Evich 601
(Output)
Betty Boop 201
Norma Cord 401
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line from _ _DATA_ _ is assigned to $_ until all the lines have been processed. The line $_ is printed only if it matches a pattern containing a space, followed by four alphanumeric word characters, \w, followed by a space and a digit, \d. The metasymbol \w represents the character class [A–Za–z0–9_].
|
Example 9.10.
(The Script)
# The word metasymbols
1 while(<DATA>){
2 print if /\W\w\w\w\w\W/
}
_ _DATA_ _
Steve Blenheim 101
Betty Boop 201
Igor Chevsky 301
Norma Cord 401
Jonathan DeLoach 501
Karen Evich 601
(Output)
Betty Boop 201
Norma Cord 401
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line from _ _DATA_ _ is assigned to $_ until all the lines have been processed. The line $_ is printed only if $_ matches a pattern containing a non-alphanumeric word character, followed by four alphanumeric word characters, \w, followed by another nonalphanumeric word character, \W. The metasymbol \W represents the character class [^A–Za–z0–9_]. Both Boop and Cord are four word characters surrounded by whitespace (nonalphanumeric characters).
|
The POSIX Character Class
Perl 5.6 introduced the POSIX character classes. POSIX (the Portable Operating System Interface) is an industry standard used to ensure that programs are portable across operating systems. In order to be portable, POSIX recognizes that different countries or locales may vary in the way characters are encoded, the symbols used to represent currency, and how times and dates are represented. To handle different types of characters, POSIX added the bracketed character class of characters shown in Table 9.3 to regular expressions.
Table 9.3. The Bracketed Character Class
| Bracket Class | Meaning |
|---|
| [:alnum:] | Alphanumeric characters |
| [:alpha:] | Alphabetic characters |
| [:ascii]: | Any character with ordinal value between 0 and 127 |
| [:cntrl:] | Control characters |
| [:digit:] | Numeric characters, 0 to 9, or \d |
| [:graph:] | Nonblank characters (not spaces, control characters, etc.) other than alphanumeric or punctuation characters |
| [:lower:] | Lowercase letters |
| [:print:] | Like [:graph:] but includes the space character |
| [:punct:] | Punctuation characters |
| [:space:] | All whitespace characters (newlines, spaces, tabs); same as \s |
| [:upper:] | Uppercase letters |
| [:word:] | Any alphanumeric or underline characters |
| [:xdigit:] | Allows digits in a hexadecimal number (0–9a–fA–F) |
The class [:alnum:] is another way of saying A–Za–z0–9. To use this class, it must be enclosed in another set of brackets for it to be recognized as a regular expression. For example, A–Za–z0–9, by itself, is not a regular expression character class, but [A–Za–z0–9] is . Likewise, [:alnum:] should be written [[:alnum:]]. The difference between using the first form, [A–Za–z0–9], and the bracketed form, [[:alnum:]], is that the first form is dependent on ASCII character encoding, whereas the second form allows characters from other languages to be represented in the class.
To negate one of the characters in the POSIX character class, the syntax is:
[^[:space:]] - all non-whitespace characters
Example 9.11.
|
Code View: (In Script)
# The POSIX character classes
1 require 5.6.0;
2 while(<DATA>){
3 print if /[[:upper:]][[:alpha:]]+ [[:upper:]][[:lower:]]+/;
}
_ _DATA_ _
Steve Blenheim
Betty Boop
Igor Chevsky
Norma Cord
Jon DeLoach
Betty Boop
Karen Evich
(Output)
Steve Blenheim
Betty Boop
Igor Chevsky
Norma Cord
Jon DeLoach
Betty Boop
Karen Evich
Perl version 5.6.0 (and above) is needed to use the POSIX character class. The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression contains POSIX character classes. The line is printed if $_ contains one uppercase letter, [[:upper:]], followed by one or more (+) alphabetic characters, [[:alpha:]], followed by an uppercase letter and one or more lowercase letters, [[:lower:]]. (The + is a regular expression metacharacter representing one or more of the previous characters and is discussed in "Metacharacters to Repeat Pattern Matches" on page 250.)
|
9.1.2. Whitespace Metacharacters
A whitespace character represents a space, tab, return, newline, or formfeed. The whitespace character can be represented literally, by pressing a Tab key or the spacebar or the Enter key.
Table 9.4. Whitespace Metacharacters
| Metacharacter | What It Matches |
|---|
| \s | Matches whitespace character, spaces, tabs, and newlines |
| \S | Matches nonwhitespace character |
| \n | Matches a newline, the end-of-line character (012 UNIX, 015 Mac OS) |
| \r | Matches a return |
| \t | Matches a tab |
| \f | Matches a form feed |
Example 9.12.
(The Script)
# The \s metasymbol and whitespace
1 while(<DATA>){
2 print if s/\s/*/g; # Substitute all spaces with stars
}
_ _DATA_ _
Steve Blenheim 101
Betty Boop 201
Igor Chevsky 301
Norma Cord 401
Jonathan DeLoach 501
Karen Evich 601
(Output)
Steve*Blenheim*101*Betty*Boop*201*Igor*Chevsky*301*Norma*
*Cord*401*Jonathan*DeLoach*501*Karen*Evich*601
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The line $_ is printed if it matches a pattern containing a whitespace character (space, tab, newline) \s. All whitespace characters are replaced with a *.
|
Example 9.13.
(The Script)
# The \S metasymbol and nonwhitespace
1 while(<DATA>){
2 print if s/\S/*/g;
}
_ _DATA_ _
Steve Blenheim 101
Betty Boop 201
Igor Chevsky 301
Norma Cord 401
Jonathan DeLoach 501
Karen Evich 601
(Output)
***** ********* ***
***** **** ***
**** ******* ***
***** **** ***
******** ******* ***
***** ****** ***
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The line $_ is printed if $_ matches a pattern containing a nonwhitespace character (not a space, tab, or newline), \S. This time, all nonwhitespace characters are replaced with a *. When a metasymbol is capitalized, it negates the meaning of the lowercase version of the metasymbol; \d is a digit; \D is a nondigit.
|
Example 9.14.
(The Script)
# Escape sequences, \n and \t
1 while(<DATA>){
2 print if s/\n/\t/;
}
_ _DATA_ _
Steve Blenheim 101
Betty Boop 201
Igor Chevsky 301
Norma Cord 401
Jonathan DeLoach 501
Karen Evich 601
(Output)
Steve Blenheim 101 Betty Boop 201 Igor Chevsky 301
Norma Cord 401 Jon DeLoach 501 Karen Evich 601
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression contains the \n escape sequence, representing a single newline character. The expression reads: Replace each newline with a tab (\t).
|
9.1.3. Metacharacters to Repeat Pattern Matches
In the previous examples, the metacharacter matched on a single character. What if you want to match on more than one character? For example, let's say you are looking for all lines containing names, and the first letter must be in uppercase—which can be represented as [A–Z]—but the following letters are lowercase, and the number of letters varies in each name. [a–z] matches on a single lowercase letter. How can you match on one or more lowercase letters? Or zero or more lowercase letters? To do this, you can use what are called quantifiers. To match on one or more lowercase letters, the regular expression can be written /[a–z]+/ where the + sign means "one or more of the previous characters," in this case, one or more lowercase letters. Perl provides a number of quantifiers, as shown in Table 9.5.
Table 9.5. The Greedy Metacharacters
| Metacharacter | What It Matches |
|---|
| x? | Matches 0 or 1 occurrences of x |
| (xyz)? | Matches 0 or 1 occurrences of pattern xyz |
| x* | Matches 0 or more occurrences of x |
| (xyz)* | Matches 0 or more occurrences of pattern xyz |
| x+ | Matches 1 or more occurrences of x |
| (xyz)+ | Matches 1 or more occurrences of pattern xyz |
| x{m,n} | Matches at least m occurrences of x and no more than n occurrences of x |
The Greed Factor
Normally, quantifiers are greedy; in other words, they match on the largest possible set of characters starting at the left-hand side of the string and searching to the right, look for the last possible character that would satisfy the condition. For example, given the following string:
$_="ab123456783445554437AB"
and the regular expression
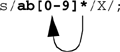
the search side would match
All of this will be replaced with an X. After the substitution, $_ would be
The asterisk (*) is a greedy metacharacter. It matches for zero or more of the preceding character. In other words, it attaches itself to the character preceding it. In the preceding example, the asterisk attaches itself to the character class [0–9]. The matching starts on the left, searching for ab followed by zero or more numbers in the range between 0 and 9. The matching continues until the last number is found; in this example, the number 7. The pattern ab and all of the numbers in the range between 0 and 9 are replaced with a single X.
Greediness can be turned off so that instead of matching on the greatest number of characters, the match is made on the least number of characters found. This is done by appending a question mark after the greedy metacharacter. See Example 9.15.
Example 9.15.
(The Script)
# The zero or one quantifier
1 while(<DATA>){
2 print if / [0-9]\.?/;
}
_ _DATA_ _
Steve Blenheim 1.10
Betty Boop .5
Igor Chevsky 555.100
Norma Cord 4.01
Jonathan DeLoach .501
Karen Evich 601
(Output)
Steve Blenheim 1.10
Igor Chevsky 555.100
Norma Cord 4.01
Karen Evich 601
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression contains the ? metacharacter, representing zero or one of the preceding characters. The expression reads: Find a space, followed by a number between 0 and 9, followed by either one literal period or no period at all.
|
Example 9.16.
(The Script)
# The zero or more quantifier
1 while(<DATA>){
2 print if /\sB[a-z]*/;
}
_ _DATA_ _
Steve Blenheim 1.10
Betty Boop .5
Igor Chevsky 555.100
Norma Cord 4.01
Jonathan DeLoach .501
Karen Evich 601
(Output)
Steve Blenheim 1.10
Betty Boop .5
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression contains the * metacharacter, representing zero or more of the preceding character. The expression reads: Find a space, \s, followed by a B and zero or more lowercase letters [a–z]*.
|
Example 9.17.
(The Script)
# The dot metacharacter and the zero or more quantifier
1 while(<DATA>){
2 print if s/[A-Z].*y/Tom/;
}
_ _DATA_ _
Steve Blenheim 101
Betty Boop 201
Igor Chevsky 301
Norma Cord 401
Jonathan DeLoach 501
Karen Evich 601
(Output)
Tom Boop 201
Tom 301
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression contains .*, where the * represents zero or more of the previous character. In this example, the previous character is the dot metacharacter, which represents any character at all. This expression reads: Find an uppercase letter, [A–Z], followed by zero or more of any character, .*, followed by the letter y. If there is more than one y on the line, the search will include all characters up until the last y. Both Betty and Igor Chevsky are matched. Note that the space in Igor Chevsky is included as one of the characters matched by the dot metacharacter.
|
Example 9.18.
(The Script)
# The one or more quantifier
1 while(<DATA>){
2 print if /5+/;
}
_ _DATA_ _
Steve Blenheim 1.10
Betty Boop .5
Igor Chevsky 555.100
Norma Cord 4.01
Jonathan DeLoach .501
Karen Evich 601
(Output)
Betty Boop .5
Igor Chevsky 555.100
Jonathan DeLoach .501
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression contains the + metacharacter, representing one or more of the preceding characters. The expression reads: Find one or more repeating occurrence of the number 5.
|
Example 9.19.
(The Script)
# The one or more quantifier
1 while(<DATA>){
2 print if s/\w+/X/g;
}
_ _DATA_ _
Steve Blenheim 101
Betty Boop 201
Igor Chevsky 301
Norma Cord 401
Jonathan DeLoach 501
Karen Evich 601
(Output)
X X X
X X X
X X X
X X X
X X X
X X X
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression contains \w followed by a + metacharacter, representing one or more alphanumeric word characters. For example, the first set of alphanumeric word characters is Steve, and Steve is replaced by an X. Since the substitution is global, the next set of alphanumeric characters, Blenheim, is replaced by an X. Lastly, the alphanumeric characters, 101, are replaced by an X.
|
Example 9.20.
(The Script)
# Repeating patterns
1 while(<DATA>){
2 print if /5{1,3}/;
}
_ _DATA_ _
Steve Blenheim 1.10
Betty Boop .5
Igor Chevsky 555.100
Norma Cord 4.01
Jonathan DeLoach .501
Karen Evich 601
(Output)
Betty Boop .5
Igor Chevsky 555.100
Jonathan DeLoach .501
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression contains the curly brace ({}) metacharacters, representing the number of times the preceding expression will be repeated. The expression reads: Find at least one occurrence of the pattern 5 and as many as three in a row.
|
Example 9.21.
(The Script)
# Repeating patterns
1 while(<DATA>){
2 print if /5{3}/;
}
_ _DATA_ _
Steve Blenheim 1.10
Betty Boop .5
Igor Chevsky 555.100
Norma Cord 4.01
Jonathan DeLoach .501
Karen Evich 601
(Output)
Igor Chevsky 555.100
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The expression reads: Find three consecutive occurrences of the pattern 5. This does not mean that the string must contain exactly three, and no more, of the number 5. It just means that there must be at least three consecutive occurrences of the number 5. If the string contained 5555555, the match would still be successful. To find exactly three occurrences of the number 5, the pattern would have to be anchored in some way, either by using the ^ and $ anchors or by placing some other character before and after the three occurrences of the number 5; for example, /^5{3}$/ or / 5{3}898/ or /95{3}\.56/.
|
Example 9.22.
(The Script)
# Repeating patterns
1 while(<DATA>){
2 print if /5{1,}/;
}
_ _DATA_ _
Steve Blenheim 1.10
Betty Boop .5
Igor Chevsky 555.100
Norma Cord 4.01
Jonathan DeLoach .501
Karen Evich 601
(Output)
Betty Boop .5
Igor Chevsky 555.100
Jonathan DeLoach .501
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The expression reads: Find at least one or more repeating occurrences of 5.
|
Metacharacters that Turn off Greediness
By placing a question mark after a greedy quantifier, the greed is turned off, and the search ends after the first match rather than the last one.
Example 9.23.
(The Script)
# Greedy and not greedy
1 $_="abcdefghijklmnopqrstuvwxyz";
2 s/[a-z]+/XXX/;
3 print $_, "\n";
4 $_="abcdefghijklmnopqrstuvwxyz";
5 s/[a-z]+?/XXX/;
6 print $_, "\n";
(Output)
3 XXX
6 XXXbcdefghijklmnopqrstuvwxyz
The scalar $_ is assigned a string of lowercase letters. The regular expression reads: Search for one or more lowercase letters, and replace them with XXX. The + metacharacter is greedy. It takes as many characters as match the expression; i.e., it starts on the left-hand side of the string, grabbing as many lowercase letters as it can find until the end of the string. The value of $_ is printed after the substitution. The scalar $_ is assigned a string of lowercase letters. The regular expression reads: Search for one or more lowercase letters, and, after finding the first one, stop searching and replace it with XXX. The ? affixed to the + turns off the greediness of the metacharacter. The minimal number of characters is searched for. The value of $_ is printed after the substitution.
|
Table 9.6. Turning Off Greediness
| Metacharacter | What It Matches |
|---|
| x?? | Matches 0 or 1 occurrences of x |
| (xyz)?? | Matches 0 or 1 occurrences of pattern xyz |
| x*? | Matches 0 or more occurrences of x |
| (xyz)*? | Matches 0 or more occurrences of pattern xyz |
| x+? | Matches 1 or more occurrences of x |
| (xyz)+? | Matches 1 or more occurrences of pattern xyz |
| x{m,n}? | Matches at least m occurrences of x and no more than n occurrences of x |
| x{m}? | Matches at least m occurrences of x |
| x{m,}? | Matches at least m times |
Example 9.24.
(The Script)
# A greedy quantifier
1 $string="I got a cup of sugar and two cups of flour
from the cupboard.";
2 $string =~ s/cup.*/tablespoon/;
3 print "$string\n";
# Turning off greed
4 $string="I got a cup of sugar and two cups of flour
from the cupboard.";
5 $string =~ s/cup.*?/tablespoon/;
6 print "$string\n";
(Output)
3 I got a tablespoon
6 I got a tablespoon of sugar and two cups of flour from the cupboard.
The scalar $string is assigned a string containing the pattern cup three times. The s (substitution) operator searches for the pattern cup followed by zero or more characters; that is, cup and all characters to the end of the line are matched and replaced with the string tablespoon. The .* is called a greedy quantifier because it matches for the largest possible pattern. The output shows the result of a greedy substitution. The scalar $string is reset. This time the search is not greedy. By appending a question mark to the .*, the smallest pattern that matches cup, followed by zero or more characters, is replaced with tablespoon. The new string is printed.
|
Anchoring Metacharacters
Often, it is necessary to anchor a metacharacter so that it matches only if the pattern is found at the beginning or end of a line, word, or string. These metacharacters are based on a position just to the left or to the right of the character that is being matched. Anchors are technically called zero-width assertions because they correspond to positions, not actual characters in a string. For example, /^abc/ means: Find abc at the beginning of the line, where the ^ represents a position, not an actual character.
Table 9.7. Anchors (Assertions)
| Metacharacter | What It Matches |
|---|
| ^ | Matches to beginning of line or beginning of string |
| $ | Matches to end of line or end of a string |
| \A | Matches the beginning of the string only |
| \Z | Matches the end of the string or line |
| \z | Matches the end of string only |
| \G | Matches where previous m//g left off |
| \b | Matches a word boundary (when not inside [ ]) |
| \B | Matches a nonword boundary |
Example 9.25.
(The Script)
# Beginning of line anchor
1 while(<DATA>){
2 print if /^[JK]/;
}
_ _DATA_ _
Steve Blenheim 1.10
Betty Boop .5
Igor Chevsky 555.100
Norma Cord 4.01
Jonathan DeLoach .501
Karen Evich 601
(Output)
Jonathan DeLoach .501
Karen Evich 601.100
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression contains the caret (^) metacharacter, representing the beginning of line anchor only when it is the first character in the pattern. The expression reads: Find a J or K at the beginning of the line. \A would produce the same result as the caret in this example. The expression /^[^JK]/ reads: Search for a non-J or non-K character at the beginning of the line. Remember that when the caret is within a character class, it negates the character class. It is a beginning of line anchor only when positioned directly after the opening delimiter.
|
Example 9.26.
(The Script)
# End of line anchor
1 while(<DATA>){
2 print if /10$/;
}
_ _DATA_ _
Steve Blenheim 1.10
Betty Boop .5
Igor Chevsky 555.10
Norma Cord 4.01
Jonathan DeLoach .501
Karen Evich 601
(Output)
Steve Blenheim 1.10
Igor Chevsky 555.10
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression contains the $ metacharacter, representing the end of line anchor only when the $ is the last character in the pattern. The expression reads: Find a 1 and a 0 followed by a newline.
|
Example 9.27.
(The Script)
# Word anchors or boundaries
1 while(<DATA>){
2 print if /\bJon/;
}
_ _DATA_ _
Steve Blenheim 1.10
Betty Boop .5
Igor Chevsky 555.100
Norma Cord 4.01
Jonathan DeLoach .501
Karen Evich 601
(Output)
Jonathan DeLoach .501
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression contains the \b metacharacter, representing a word boundary. The expression reads: Find a word beginning with the pattern Jon.
|
Example 9.28.
(The Script)
# Beginning and end of word anchors
1 while(<DATA>){
2 print if /\bJon\b/;
}
_ _DATA_ _
Steve Blenheim 1.10
Betty Boop .5
Igor Chevsky 555.100
Norma Cord 4.01
Jonathan DeLoach .501
Karen Evich 601
(Output)
<No output>
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression also contains the \b metacharacter, representing a word boundary. The expression reads: Find a word beginning and ending with Jon. Nothing is found.
|
The m Modifier
The m modifier is used to control the behavior of the $ and ^ anchor metacharacters. A string containing newlines will be treated as multiple lines. If the regular expression is anchored with the ^ metacharacter, and that pattern is found at the beginning of any one of the multiple lines, the match is successful. Likewise, if the regular expression is anchored by the $ metacharacter (or \Z) at the end of any one of the multiple lines, and the pattern is found, it too will return a successful match. The m modifier has no effect with \A and \z.
Example 9.29.
(The Script)
# Anchors and the m modifier
1 $_="Today is history.\nTomorrow will never be here.\n";
2 print if /^Tomorrow/; # Embedded newline
3 $_="Today is history.\nTomorrow will never be here.\n";
4 print if /\ATomorrow/; # Embedded newline
5 $_="Today is history.\nTomorrow will never be here.\n";
6 print if /^Tomorrow/m;
7 $_="Today is history.\nTomorrow will never be here.\n";
8 print if /\ATomorrow/m;
9 $_="Today is history.\nTomorrow will never be here.\n";
10 print if /history\.$/m;
(Output)
6 Today is history.
Tomorrow will never be here.
10 Today is history.
Tomorrow will never be here.
The $_ scalar is assigned a string with embedded newlines. The ^ metacharacter anchors the search to the beginning of the line. Since the line does not begin with Tomorrow, the search fails and nothing is returned. The $_ scalar is assigned a string with embedded newlines. The \A assertion matches only at the beginning of a string, no matter what. Since the string does not begin with Tomorrow, the search fails and nothing is returned. The $_ scalar is assigned a string with embedded newlines. The m modifier treats the string as multiple lines, each line ending with a newline. In this example, the ^ anchor matches at the beginning of any of these multiple lines. The pattern /^Tomorrow/ is found in the second line. The $_ scalar is assigned a string with embedded newlines. The \A assertion matches only at the beginning of a string, no matter how many newlines are embedded, and the m modifier has no effect. Since Tomorrow is not found at the beginning of the string, nothing is matched. The $_ scalar is assigned a string with embedded newlines. The $ metacharacter anchors the search to the end of a line. With the m modifier, embedded newlines create multiple lines. The pattern /history\.$/ is found at the end of the first line. This will also work with the \Z assertion but not with \z.
|
Alternation
Alternation allows the regular expression to contain alternative patterns to be matched. For example, the regular expression /John|Karen|Steve/ will match a line containing John or Karen or Steve. If Karen, John, or Steve are all on different lines, all lines are matched. Each of the alternative expressions is separated by a vertical bar (pipe symbol) and the expressions can consist of any number of characters, unlike the character class that matches for only one character; e.g., /a|b|c/ is the same as [abc], whereas /ab|de/ cannot be represented as [abde]. The pattern /ab|de/ is either ab or de, whereas the class [abcd] represents only one character in the set, a, b, c, or d.
Example 9.30.
(The Script)
# Alternation: this, that, and the other thing
1 while(<DATA>){
2 print if /Steve|Betty|Jon/;
}
_ _DATA_ _
Steve Blenheim
Betty Boop
Igor Chevsky
Norma Cord
Jonathan DeLoach
Karen Evich
(Output)
2 Steve Blenheim
Betty Boop
Jonathan DeLoach
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The pipe symbol, |, is used in the regular expression to match on a set of alternative patterns. If any of the patterns Steve, Betty, or Jon, are found, the match is successful.
|
Grouping or Clustering
If the regular expression pattern is enclosed in parentheses, a subpattern is created. Then, for example, instead of the greedy metacharacters matching on zero, one, or more of the previous single character, they can match on the previous subpattern. Alternation can also be controlled if the patterns are enclosed in parentheses. This process of grouping characters together is also called clustering by the Perl wizards.
Example 9.31.
(The Script)
# Clustering or grouping
1 $_=qq/The baby says, "Mama, Mama, I can say Papa!"\n/;
2 print if s/(ma|pa)+/goo/gi;
(Output)
The baby says, "goo, goo, I can say goo!"
The $_ scalar is assigned the doubly quoted string. The regular expression contains a pattern enclosed in parentheses, followed by a + metacharacter. The parentheses group the characters that are to be controlled by the + metacharacter. The expression reads: Find one or more occurrences of the pattern ma or pa and replace that with goo.
|
Example 9.32.
(The Script)
# Clustering or grouping
1 while(<DATA>){
2 print if /\s(12){3}$/; # Print lines matching exactly 3
# consecutive occurrences of 12 at
# the end of the line
}
_ _DATA_ _
Steve Blenheim 121212
Betty Boop 123
Igor Chevsky 123444123
Norma Cord 51235
Jonathan DeLoach123456
Karen Evich 121212456
(Output)
Steve Blenheim 121212
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The pattern 12 is grouped in parentheses. It is controlled by the quantifier {3}; i.e., a row of exactly 3 occurrences of 12 at the end of the line ($) will be matched.
|
Example 9.33.
The Script)
# Clustering or grouping
1 $_="Tom and Dan Savage and Ellie Main are cousins.\n";
2 print if s/Tom|Ellie Main/Archie/g;
3 $_="Tom and Dan Savage and Ellie Main are cousins.\n";
4 print if s/(Tom|Ellie) Main/Archie/g;
(Output)
2 Archie and Dan Savage and Archie are cousins.
4 Tom and Dan Savage and Archie are cousins.
The $_ scalar is assigned the string. If either the pattern Tom or the pattern Ellie Main is matched in $_, both patterns will be replaced with Archie. The $_ scalar is assigned the string. By enclosing Tom and Ellie in parentheses, the alternative now becomes either Tom Main or Ellie Main. Since the pattern Ellie Main is the only one matched in $_, Ellie Main is replaced with Archie.
|
Example 9.34.
(The Script)
# Clustering and anchors
1 while(<DATA>){
2 # print if /^Steve|Boop/;
3 print if /^(Steve|Boop)/;
}
_ _DATA_ _
Steve Blenheim
Betty Boop
Igor Chevsky
Norma Cord
Jonathan DeLoach
Karen Evich
(Output)
Steve Blenheim
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. This line has been commented. It would print any line that begins with Steve and any line containing the pattern Boop. The beginning of line anchor, the caret, applies only to the pattern Steve. The line will be printed if it begins with either Steve or Boop. The parentheses group the two patterns so that the beginning of line anchor, the caret, applies to both patterns Steve and Boop. It could also be written as /(^Steve|^Boop)/.
|
Remembering or Capturing
If the regular expression pattern is enclosed in parentheses, a subpattern is created. The subpattern is saved in special numbered scalar variables, starting with $1, then $2, and so on. These variables can be used later in the program and will persist until another successful pattern match occurs, at which time they will be cleared. Even if the intention was to control the greedy metacharacter or the behavior of alternation as shown in the previous example, the subpatterns are saved as a side effect.
Example 9.35.
|
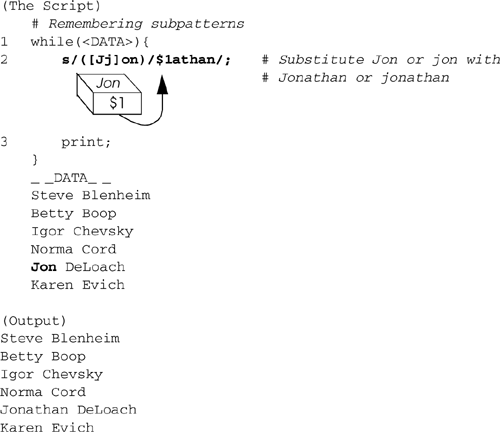
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression contains the pattern Jon enclosed in parentheses. This pattern is captured and stored in a special scalar, $1, so it can be remembered. If a second pattern is enclosed in parentheses, it will be stored in $2, and so on. The numbers are represented on the replacement side as $1, $2, $3, and so on. The expression reads: Find Jon or jon and replace with either Jonathan or jonathan, respectively. The special numbered variables are cleared after the next successful search is performed.
|
Example 9.36.
|

The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression contains two patterns enclosed in parentheses. The first pattern is captured and saved in the special scalar $1, and the second pattern is captured and saved in the special scalar $2. On the replacement side, since $2 is referenced first, Blenheim is printed first, followed by a comma and then by $1, which is Steve (i.e., the effect is to reverse Steve and Blenheim).
|
Example 9.37.
(The Script)
# Reversing subpatterns
1 while(<DATA>){
2 s/([A-Z][a-z]+)\s([A-Z][a-z]+)/$2, $1/;
# Reverse first and last names
3 print;
}
_ _DATA_ _
Steve Blenheim
Betty Boop
Igor Chevsky
Norma Cord
Jon DeLoach
Karen Evich
(Output)
Blenheim, Steve
Boop, Betty
Chevsky ,Igor
Cord, Norma
De, JonLoach # Whoops!
Evich, Karen
This regular expression also contains two patterns enclosed in parentheses. In this example, metacharacters are used in the pattern matching process. The first pattern reads: Find an uppercase letter followed by one or more lowercase letters. A space follows the remembered pattern. The second pattern reads: Find an uppercase letter followed by one or more lowercase letters. The patterns are saved in $1 and $2, respectively, and then reversed on the replacement side. Note the problem that arises with the last name DeLoach. That is because DeLoach contains both uppercase and lowercase letters after the first uppercase letter in the name. To allow for this case, the pattern should be s/([A–Z][a–z]+)\s([A–Z][A–Za–z]+)/$2, $1/.
|
Example 9.38.
(The Script)
# Metasymbols and subpatterns
1 while(<DATA>){
2 s/(\w+)\s(\w+)/$2, $1/; # Reverse first and last names
3 print;
}
_ _DATA_ _
Steve Blenheim
Betty Boop
Igor Chevsky
Norma Cord
Jon DeLoach
Betty Boop
(Output)
Blenheim, Steve
Boop, Betty
Chevsky, Igor
Cord, Norma
DeLoach, Jon
Boop, Betty
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression contains two subpatterns enclosed in parentheses. The \w+ represents one or more word characters. The regular expression consists of two parenthesized subpatterns (called backreferences) separated by a space (\s). Each subpattern is saved in $1 and $2, respectively. $1 and $2 are used in the replacement side of the substitution to reverse the first and last names.
|
Example 9.39.
(The Script)
# Backreferencing
1 while(<DATA>){
2 ($first, $last)=/(\w+) (\w+)/; # Could be: (\S+) (\S+)/
3 print "$last, $first\n";
}
_ _DATA_ _
Steve Blenheim
Betty Boop
Igor Chevsky
Norma Cord
Jon DeLoach
Betty Boop
(Output)
Blenheim, Steve
Boop, Betty
Chevsky, Igor
Cord, Norma
DeLoach, Jon
Boop, Betty
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression contains two patterns enclosed in parentheses. The \w+ represents one or more word characters. The regular expression consists of two parenthesized patterns (called backreferences). The return value is an array of all the backreferences. Each word is assigned to $first and $last, respectively. The values of the variables are printed for each line of the file.
|
Example 9.40.
(The Script)
# The greedy quantifier
1 $string="ABCdefghiCxyzwerC YOU!";
2 $string=~s/.*C/HEY/;
3 print "$string", "\n";
(Output)
HEY YOU!
The scalar $string is assigned a string containing a number of the pattern C. The search side of the substitution, /.*C/, reads: Find the largest pattern that contains any number of characters ending in C. This search is greedy. It will search from left to right until it reaches the last C. The string HEY will replace what was found in $string. The new string is printed showing the result of the substitution.
|
Example 9.41.
(The Script)
# Backreferencing and greedy quantifiers
1 $string="ABCdefghiCxyzwerC YOU!";
2 $string=~s/(.*C)(.*)/HEY/; # Substitute the whole string with HEY
3 print $1, "\n";
4 print $2, "\n";
5 print "$string\n";
(Output)
3 ABCdefghiCxyzwerC
4 YOU!
5 HEY
The scalar $string is assigned the string. The /*.C/ regular expression is enclosed in parentheses. The pattern found will be stored in the $1 special variable. Whatever is left will be stored in $2. The largest possible pattern was stored in $1. It is printed. The remainder of the string was stored in $2. It is printed. The entire string was replaced with HEY after the substitution.
|
Example 9.42.
(The Script)
# Backreferencing and greed
1 $fruit="apples pears peaches plums";
2 $fruit =~ /(.*)\s(.*)\s(.*)/;
3 print "$1\n";
4 print "$2\n";
5 print "$3\n";
print "-" x 30, "\n";
6 $fruit="apples pears peaches plums";
7 $fruit =~ /(.*?)\s(.*?)\s(.*?)\s/; # Turn off greedy quantifier
8 print "$1\n";
9 print "$2\n";
10 print "$3\n";
(Output)
3 apples pears
4 peaches
5 plums
------------------------------
8 apples
9 pears
10 peaches
The scalar $fruit is assigned the string. The string is divided into three remembered substrings, each substring enclosed within parentheses. The .* metacharacter sequence reads zero or more of any character. The * always matches for the largest possible pattern. The largest possible pattern would be the whole string. However, there are two whitespaces outside of the parentheses that must also be matched in the string. What is the largest possible pattern that can be saved in $1 and still leave two spaces in the string? The answer is apples pears. The value of $1 is printed. The first substring was stored in $1. peaches plums is what remains of the original string. What is the largest possible pattern (.*) that can be matched and still have one whitespace remaining? The answer is peaches. peaches will be assigned to $2. The value of $2 is printed. The third substring is printed. plums is all that is left for $3. The scalar $fruit is assigned the string again. This time, a question mark follows the greedy quantifier (*). This means that the pattern saved will be the minimal, rather than the maximal, number of characters found. apples will be the minimal numbers of characters stored in $1, pears the minimal number in $2, and peaches the minimal number of characters in $3. The \s is required or the minimal amount of characters would be zero, since the * means zero or more of the preceding character. The value of $1 is printed. The value of $2 is printed. The value of $3 is printed.
|
Turning Off Capturing
When the only purpose is to use the parentheses for grouping, and you are not interested in saving the subpatterns in $1, $2, or $3, the special ?: metacharacter can be used to suppress the capturing of the subpattern.
Example 9.43.
(In Script)
1 $_="Tom Savage and Dan Savage are brothers.\n";
2 print if /(?:D[a-z]*|T[a-z]*) Savage/; # Perl will not capture
# the pattern
3 print $1,"\n"; # $1 has no value
(Output)
2 Tom Savage and Dan Savage are brothers.
3 <Nothing is printed>
The $_ scalar is assigned a string. The ?: turns off capturing when a pattern is enclosed in parentheses. In this example, alternation is used to search for any of two patterns. If the search is successful, the value of $_ is printed, but whichever pattern is found, it will not be captured and assigned to $1. Without the ?:, the value of $1 would be Tom, since it is the first pattern found. ?: says "Don't save the pattern when you find it." Nothing is saved and nothing is printed.
|
Metacharacters that Look Ahead and Behind
Looking ahead and looking behind in a string for a particular pattern gives you further control of a regular expression.
With a positive look ahead, Perl looks forward or ahead in the string for a pattern (?=pattern) and if that pattern is found, will continue pattern matching on the regular expression. A negative look ahead looks ahead to see if the pattern (?!pattern) is not there, and if it is not, finishes pattern matching.
With a positive look behind, Perl looks backward in the string for a pattern (?<=pattern) and if that pattern is found, will then continue pattern matching on the regular expression. A negative look behind looks behind in the string to see if a pattern (?<!pattern) is not there, and if it is not, finishes the matching.
Table 9.8. Look Around Assertions
| Metacharacter | What It Matches |
|---|
| /PATTERN(?=pattern)/ | Positive look ahead |
| /PATTERN(?!pattern)/ | Negative look ahead |
| (?<=pattern)/PATTERN/ | Positive look behind |
| (?<!pattern)/PATTERN/ | Negative look behind |
Example 9.44.
(The Script)
# A positive look ahead
1 $string="I love chocolate cake and chocolate ice cream.";
2 $string =~ s/chocolate(?= ice)/vanilla/;
3 print "$string\n";
4 $string="Tomorrow night Tom Savage and Tommy Johnson will leave
for vacation.";
5 $string =~ s/Tom(?=my)/Jere/g;
6 print "$string\n";
(Output)
3 I love chocolate cake and vanilla ice cream.
6 Tomorrow night Tom Savage and Jeremy Johnson will leave for vacation.
The scalar $string contains chocolate twice; the word cake follows the first occurrence of chocolate, and the word ice follows the second occurrence. This is an example of a positive look ahead. The pattern chocolate is followed by (?=ice) meaning, if chocolate is found, look ahead (?=) and see if ice is the next pattern. If ice is found just ahead of chocolate, the match is successful and chocolate will be replaced with vanilla. After the substitution on line 2, the new string is printed. The scalar $string is assigned a string of text consisting of three words starting with Tom. The pattern is matched if it contains Tom, only if Tom is followed by my. If the positive look ahead is successful, then Tom will be replaced with Jere in the string. After the substitution on line 5, the new string is printed. Tommy has been replaced with Jeremy.
|
Example 9.45.
(The Script)
# A negative look ahead
1 while(<DATA>){
2 print if/^\w+\s(?![BC])/;
}
_ _DATA_ _
Steve Blenheim
Betty Boop
Igor Chevsky
Norma Cord
Jon DeLoach
Karen Evich
(Output)
Jon DeLoach
Karen Evich
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The regular expression means: Search at the beginning of the line for one or more word characters (\w+), followed by a space (\s), and look ahead for any character that is not a B or C. This is called a negative look ahead.
|
Example 9.46.
(The Script)
# A positive look behind
1 $string="I love chocolate cake, chocolate milk,
and chocolate ice cream.";
2 $string =~ s/(?<= chocolate) milk/ candy bars/;
3 print "$string\n";
4 $string="I love coffee, I love tea, I love the boys
and the boys love me.";
5 $string =~ s/(?<=the boys) love/ don't like/;
6 print "$string\n";
(Output)
3 I love chocolate cake, chocolate candy bars, and chocolate ice cream.
6 I love coffee, I love tea, I love the boys and the boys don't like me.
The scalar $string is assigned a string with three different occurrences of chocolate. The pattern in parentheses is called a positive look behind, meaning that Perl looks backward in the string to make sure this pattern occurs. If the pattern milk is found, Perl will look back in the string to see if it is preceded by chocolate and, if so, milk will be replaced with candy bars. The string is printed after the substitution. This is another example of a positive look behind. Perl looks backward in the string for the pattern the boys, and if the pattern is found, the regular expression love will be replaced with don't like.
|
Example 9.47.
(The Script)
# A negative look behind
1 while(<DATA>){
2 print if /(?<!Betty) B[a-z]*/;
}
_ _DATA_ _
Steve Blenheim
Betty Boop
Igor Chevsky
Norma Cord
Jon DeLoach
Karen Evich
(Output)
Steve Blenheim
The special DATA filehandle gets its input from the text after the _ _DATA_ _ token. The while loop is entered and the first line after the _ _DATA_ _ token is read in and assigned to $_. Each time the loop is entered, the next line following _ _DATA_ _ is assigned to $_ until all the lines have been processed. The pattern in parentheses is called a negative look behind, meaning that Perl looks backward in the string to make sure this pattern does not occur. Any line that contains the letter B, followed by zero or more lowercase letters, [a–z]*, will be printed, as long as the pattern behind it is not Betty.
|
9.1.4. The tr or y Function
The tr function translates characters, in a one-on-one correspondence, from the characters in the search string to the characters in the replacement string. tr returns the number of characters it replaced. The tr function does not interpret regular expression metacharacters but allows a dash to represent a range of characters. The letter y can be used in place of tr. This strangeness comes from UNIX, where the sed utility has a y command to translate characters, similar to the UNIX tr. This illustrates the role UNIX has played in the development of Perl.
The d option deletes the search string.
The c option complements the search string.
The s option is called the squeeze option. Multiple occurrences of characters found in the search string are replaced by a single occurrence of that character (e.g., you may want to replace multiple tabs with single tabs). See Table 9.9 for a list of modifiers.
Table 9.9. tr Modifiers
| Modifier | Meaning |
|---|
| d | Delete characters |
| c | Complement the search list |
| s | Squeeze out multiple characters to single character |
tr/search/replacement/
tr/search/replacement/d
tr/search/replacement/c
tr/search/replacement/s
y/search/replacement/ (same as tr; uses same modifiers)
|
Example 9.48.
|
Code View: (The Input Data)
Steve Blenheim 101
Betty Boop 201
Igor Chevsky 301
Norma Cord 401
Jon DeLoach 501
Karen Evich 601
(Lines from a Script)
1 tr/a-z/A-Z/;print;
(Output)
STEVE BLENHEIM 101
BETTY BOOP 201
IGOR CHEVSKY 301
NORMA CORD 401
JON DELOACH 501
KAREN EVICH 601
2 tr/0-9/:/; print;
(Output)
Steve Blenheim :::
Betty Boop :::
Igor Chevsky :::
Norma Cord :::
Jon DeLoach :::
Karen Evich :::
3 tr/A–Z/a–c/;print;
(Output)
cteve blenheim 101
betty boop 201
cgor chevsky 301
corma cord 401
con cecoach 501
caren cvich 601
4 tr/ /#/; print;
(Output)
Steve#Blenheim#101
Betty#Boop#201
Igor#Chevsky#301
Norma#Cord#401
Jon#DeLoach#501
Karen#Evich#601
5 y/A–Z/a–z/;print;
(Output)
steve blenheim 101
betty boop 201
igor chevsky 301
norma cord 401
jon deloach 501
karen evich 601
The tr function makes a one-on-one correspondence between each character in the search string with each character in the replacement string. Each lowercase letter will be translated to its corresponding uppercase letter. Each number will be translated to a colon. The translation is messy here. Since the search side represents more characters than the replacement side, all letters from D to Z will be replaced with a c. Each space will be replaced with pound signs (#). The y is a synonym for tr. Each uppercase letter is translated to its corresponding lowercase letter.
|
The tr Delete Option
The d (delete) option removes all characters in the search string not found in the replacement string.
Example 9.49.
1 tr/ //; print;
(Output)
1 Steve Blenheim
2 Betty Boop
3 Igor Chevsky
4 Norma Cord
5 Jon DeLoach
6 Karen Evich
2 tr/ //d;print;
(Output)
1SteveBlenheim
2BettyBoop
3IgorChevsky
4NormaCord
5JonDeLoach
6KarenEvich
In this example, the translation does not take place as it would if you were using sed or vi. The d option is required to delete each space when using the tr function.
|
The tr Complement Option
The c (complement) option complements the search string; that is, it translates each character not listed in this string to its corresponding character in the replacement string.
Example 9.50.
1 tr/0-9/*/; print;
(Output)
* Steve Blenheim
* Betty Boop
* Igor Chevsky
* Norma Cord
* Jon DeLoach
* Karen Evich
2 tr/0-9/*/c; print;
(Output)
1****************2************3**************4************5****
*********6*************
Without the c option, tr translates each number to an asterisk (*). With the c option, tr translates each character that is not a number to an asterisk (*); this includes the newline character.
|
The tr Squeeze Option
The s (squeeze) option translates all characters that are repeated to a single character and can be used to get rid of excess characters, such as excess whitespace or delimiters, sqeezing these characters down to just one.
Example 9.51.
(The Text File)
1 while (<DATA>){
tr/:/:/s;
print;
{
_ _DATA_ _
1:::Steve Blenheim
2::Betty Boop
3:Igor Chevsky
4:Norma Cord
5:::::Jon DeLoach
6:::Karen Evich
(Output)
1:Steve Blenheim
2:Betty Boop
3:Igor Chevsky
4:Norma Cord
5:Jon DeLoach
6:Karen Evich
The "squeeze" option causes the multiple colons to be translated (squeezed) to single colons.
|