Until now, we have been storing data in ordinary text files with Perl by creating user-defined filehandles. We have also looked at Perl's DBM mechanism for storing data in binary files as simple hashes. But text files and DBM files are limited when you need to efficiently store and manage large amounts of data: for example, to maintain a business such as a hospital, research lab, bank, college, or Web site. A relational database system follows certain standards and has a number of features for storing large collections of data. The data is managed so that retrieving, updating, inserting, and deleting data is relatively easy and takes the least amount of time. The database management system must store the data so that it maintains its integrity; i.e., the data is accurate and is protected from being accessed by unauthorized users, the data is secure.
Introduced in the 1970s, the relational model made data manipulation easier and faster for the end users and easier to maintain by the administrator. At the core of this model is the concept of a relation, visually represented as a table in which all data is stored. The data is represented by different types, such as a string, number, date, etc. Each table is made up of records consisting of horizontal rows and vertical columns or fields, like a two-dimensional array. Tables in the database relate to each other; e.g., if you have a database called "school," it might consist of tables called "student," "teacher," "course," etc. The student takes a course from a teacher who teaches one or many courses. The data can be retrieved and manipulated for just the student, teacher, or course, but also joined together based on some common key field. The Structured Query Language (SQL) is used to "talk to" realtional databases, making it easy to retrieve, insert, update, and delete data from the tables in the database.
Due to the popularity of relational databases, known as relational database management systems (RDBMS), a number of relational databases are used today, among them Oracle, Sybase, PostgreSQL Informix, SQL server, and MySQL.
Relational databases use a client/server model. Today, MySQL is one of the most popular client/server database systems in the open source community.
Figure 17.1 shows the model for a client/server architecture. The user goes to the command line and starts the MySQL client to issue MySQL commands. The client makes a request to the MySQL server, which in turn sends a query to the database. The database sends the results of the query back to the server, and the results are displayed in the client's window. In the second scenario, rather than using the command-line client, a Perl script makes a connection to the database server through a database interface that acts as an interpreter. If a Perl script contains an instruction to connect to a database, in this case MySQL, then once the connection is made and a database selected, the Perl program has access to the database through the MySQL server. The MySQL server receives requests, called queries, from the Perl program and sends back information collected from the database. In the third example, the user requests a page from the browser (the client); an HTTP connection is made to the Web server (Apache, ISS), where the request is received and handled. If the action is to start up a Perl program, the Web server may use the Common Gateway Interface (CGI) to start up the Perl interpreter, and Perl starts processing the information that was sent from the HTTP server to format and send it back to the Web server, or if a request to the database server is made, then the steps to connect, query, and get results from the database are carried out. Figure 17.1 shows the client/server relationship between the MySQL client and the MySQL server, and the client/server realtionship between the Web browser, Web server Perl program, and the MySQL database server. By the end of this chapter, you will be able to get information sent from a Web browser (client) to a Web server and from the Web server to a Perl CGI program, which can connect to a database server to retrieve and store information from a MySQL database.

What makes up a database? The main components of a relational database management system are:
We will discuss each of these concepts in the next sections of this chapter. Figure 17.2 illustrates their relationship to each other.
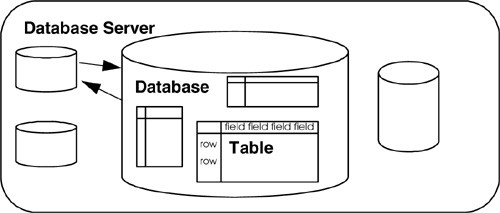
The database server is the actual server process running the databases. It controls the storage of the data, grants access to users, updates and deletes records, and communicates with other servers. The database server is normally on a dedicated host computer, serving and managing multiple clients over a network, but can also be used as a standalone server on the local host machine to serve a single client; e.g., you may be the single client using MySQL on your local machine, often referred to as "localhost," without any network connection at all. This is probably the best way to learn how to use MySQL.
If you are using MySQL, the server process is the mysql service on Windows or the mysqld process on Linux/UNIX operating systems. The database server typically follows the client/server model, where the front end is the client, a user sitting at his workstation making database requests and waiting for results, while the back end is the database server that grants access to users, stores and manipulates the data, performs backups, even talks to other servers. The requests to the database server can also be made from a program that acts on behalf of a user making requests from a Web page or a program. In the following chapters, you will learn how to make requests from the MySQL command line first and then to connect to the database server from a Perl program using Perl built-in functions to make requests to the MySQL database server, and finally how to make a request from a Web form and send the request to a Perl program and then onto MySQL.
A database is a collection of related data elements, usually corresponding to a specific application. A company may have one database for all its HR needs, perhaps another for its sales staff, and a third for e-commerce applications, etc. Figure 17.3 lists the databases installed on a particular version of MySQL. The databases are listed as "mysql", "northwind", "phpmyadmin", and "test".

Each database consists of two-dimensional tables identified by unique names. In fact, a relational database stores all of its data in tables, and nothing more. All operations are performed on the table, which can then produce other tables, etc.
One of the first decisions you will make when designing a database is what tables it will contain. A typical database for an organization might consist of tables for customers, orders, and products. All these tables are related to one another in some way. For example, customers have orders and orders have items. Although each table exists on its own, collectively the tables comprise a database. Figure 17.4 lists the tables in a database called "northwind",[2] a fictional database provided by Microsoft to serve as a model for learning how to manipulate a database. (This should be on the CD provided with this book.)
[2] The Northwind Traders sample database typically comes as a free sample with Microsoft Access but is available for MySQL at http://www.flash-remoting.com/examples/.

A table has a name and consists of a set of rows and columns. It resembles a spreadsheet where each row, also called a record, is comprised of vertical columns, also called fields. All rows from the same table have the same set of columns. The "shippers" table from the "northwind" database has three columns and three rows.

There are two basic operations you can perform on a relational table. You can retrieve a subset of its columns and you can retrieve a subset of its rows. Figures 17.6 and 17.7 are samples of the two operations.


Remember: a relational database manipulates only tables, and the results of all operations are also tables, called result sets. The tables are sets, which are themselves sets of rows and columns. The database itself is a set of tables.
You can also perform a number of other operations between two tables, treating them as sets: you can join information from two tables, make cartesian products of the tables, get the intersection between two tables, add one table to another, and so on. Later we'll show you how to perform operations on tables using the SQL language.
Columns are an integral part of a database table. Columns are also known as fields, or attributes. Fields describe the data. Each field has a name. For example, the "shippers" table has fields named "ShipperID", "CompanyName" and "Phone". The field also describes the type of data it contains. A data type can be a number, a character, a date, a time stamp, etc. In Figure 17.8 the ShipperID is the name of a field, the data type is an integer, and the shipper's ID will not exceed 11 numbers. There are many data types and sometimes they are specific to a particular database system; e.g., MySQL may have different data types available than Oracle. We will learn more about the MySQL data types in the next chapter.

A record is a row in the table. It could be a product in the product table, an employee record in the employee table, and so on. Each table is a database contains zero or more records. Figure 17.9 shows us that there are three records in the "shippers" table.

A primary key is a unique identifier for each record. For example, every employee in the United States has a Social Security Number, every driver has a driver's license, and every car has a license plate. These identifiers are unique. In the database world, the unique identifier is called a primary key. Although it is a good idea to have a primary key, not every table has one. The primary key is determined when the table is created and is more in keeping with a discussion on database design. In Figure 17.10 the "ShipperID" is the primary key for the "shippers" table in the "northwind" database. It is a unique ID that consists of a number that will automatically be incremented every time a new company (record) is added to the list of shippers.

When searching for a particular record in a table, MySQL must load all the records before it can execute the query. In addition to a primary key, one or more indexes are often used to enhance performance for finding rows in tables that are frequently accessed. Indexes are like the indexes in the back of a book that help you find a specific topic more quickly than searching through the entire book. An index, like the index of a book, is a reference to a particular record in a table.
Designing a very small database isn't difficult, but designing a database for a large Web-based application can be daunting. Database design is both an art and a science and requires an understanding of how the relational model is implemented, a topic beyond the scope of this book. When discussing the design of the database, you will encounter the term "database schema," which refers to the structure of the database. It describes the design of the database similar to a template, or blueprint; it describes all the tables and how the data will be organized but does not contain the actual data. Figure 17.11 describes the schema for the tables in the "northwind" database.

When Perl output is sent to the browser, the browser understands markup languages, such as HTML or XHTML, and these language tags are embedded in Perl's print statements, output that could be displayed as forms, images, stylized text, colors, tables, etc. Likewise, in order to communicate with the MySQL server, your Perl scripts must speak a language the database will understand. That language is called SQL. SQL stands for Structured Query Language, the language of choice for most modern multiuser relational databases. It provides the syntax and language constructs needed to talk to relational databases in a standardized, cross-platform/structured way. Like the English language with a variety of dialects (British, American, Australian, etc.), there are many different versions of the SQL language. The version of SQL used by MySQL follows the ANSI (American National Standards Institute) standard, meaning that it must support the major keywords (such as SELECT, UPDATE, DELETE, INSERT, WHERE, etc.) as defined in the standard. As you can see by the names of these keywords, SQL is the language that makes it possible to manipulate the data in a database.
If you are not familiar with SQL, refer to Appendix B for a complete guide on how to use the SQL language. There are also a number of very well-written tutorials available on the Web, such as http://www.w3schools.com/sql/default.asp, http://sqlcourse.com/select.html, http://www.1keydata.com/sql/sql.html
When you create a SQL statement, it makes a request, or "queries" the database, in the form of a statement, similar to the structure of an English imperative sentence, such as "Select your partner," "Show your stuff," "Describe that bully." The first word in a SQL statement is an English verb, an action word called a command, such as show, use, select, drop, etc. The commands are followed by a list of noun-like words, such as show databases, use datatabase, or create databases. The statement may contain prepositions, such as "in" or "from"; e.g., show tables in database or select phones from customer_table. The language also lets you add conditional clauses to refine your query, such as select companyname from suppliers where supplierid > 20;.
When listing multiple items in a query, like English, the items are separated by commas; e.g., in the following SQL statement, each field in the list being selected is comma-separated: select companyname, phone, address from suppliers;.
If the queries get very long and involved, you might want to type them into your favorite editor, because once you have executed a query, it is lost. By saving the query in an editor, you can cut and paste it back into the MySQL browser or command line without retyping it. But most importantly, make sure your query makes sense and will not cause havoc on an important database. MySQL provides a "test" database for practice.
The semicolon is the standard way to terminate each query statement. Some database systems don't require the semicolon, but MySQL does (exceptions are the USE and QUIT commands), and if you forget it, you will see a secondary prompt, and execution will go on hold until you add the semicolon.
A database and its tables are easier to read when good naming conventions are used.
For example, it makes good sense to make table names plural and field/column names singular. Why? Because a table called Shippers normally holds more than one shipper, but the name of the field used to describe each shipper is a single value, such as his company_name, phone, etc. The first letter in a table or field name is usually capitalized.
Compound names, such as "company_name," are usually separated by the underscore, with the first letter of each word capitalized, "Company_Name".
Spaces and dashes are not allowed in any name in the database.
All languages have a list of reserved words that have special meaning to the language. Most of these words will be used in this chapter. The SQL reserved words are listed in Table 17.1. (See MySQL documentation for a complete list of all reserved words.)
| CREATE | ALTER |
| INSERT | SELECT |
| FROM | ON |
| ORDER BY | JOIN |
| CROSS JOIN | RIGHT JOIN |
| DROP | DELETE |
| UPDATE | SET |
| INTO | WHERE |
| GROUP BY | LEFT JOIN |
| FULL JOIN | AND |
| LIMIT | LIKE |
| OR | AS |
Database and table names are case sensitive if you are using UNIX and not if you are using Windows. A convention is to always use lowercase names for databases and their tables.
SQL commands are not case sensitive. For example, the following SQL statements are equally valid:
show databases;
SHOW DATABASES;Although SQL commands are not case sensitive, by convention, SQL keywords are capitalized for clarity, whereas only the first letter of the field, table, and database names is capitalized.
SELECT * FROM Persons WHERE FirstName='John'
For performing pattern matching with the LIKE and NOT LIKE commands, then the pattern being searched for is case sensitive when using MySQL.
A result set is just another table created to hold the results from a SQL query. Most database software systems even allow you to perform operations on the result set with functions, such as: Move-To-First-Record, Get-Record-Content, Move-To-Next-Record, etc. In the following example, the result set is the table created by asking MySQL to show all the fields in the table called "shippers".
